




声明:本网站所有内容均为资源介绍学习参考,如有侵权请联系后删除
![[大讲台]30个小时搞定Python网络爬虫_Python网络爬虫视频教程_配课程配套资料](/uploads/allimg/200912/1-200912093012220.png)

适用人群
1、零基础对Python网络爬虫感兴趣的学员
2、想从事Python网络爬虫工程师相关工作的学员
3、想学习Python网络爬虫作为技术储备的学员
课程目标
1、本课程的目标是将大家培养成Python网络爬虫工程师。薪资基本在13k-36k左右;
2、学完能够从零开始掌握Python爬虫项目的编写,学会独立开发常见的爬虫项目;
3、学完能掌握常见的反爬处理手段,比如验证码处理、浏览器伪装、代理IP池技术和用户代理池技术等;
4、学完能够熟练使用正则表达式和XPath表达式进行信息提取;
5、学完掌握抓包技术,掌握屏蔽的数据信息如何进行提取,学会自动模拟加载行为、进行网址构造和自动模拟Ajax异步请求数据;
6、熟练掌握urllib模块,熟练使用Scrapy框架进行爬虫项目开发。
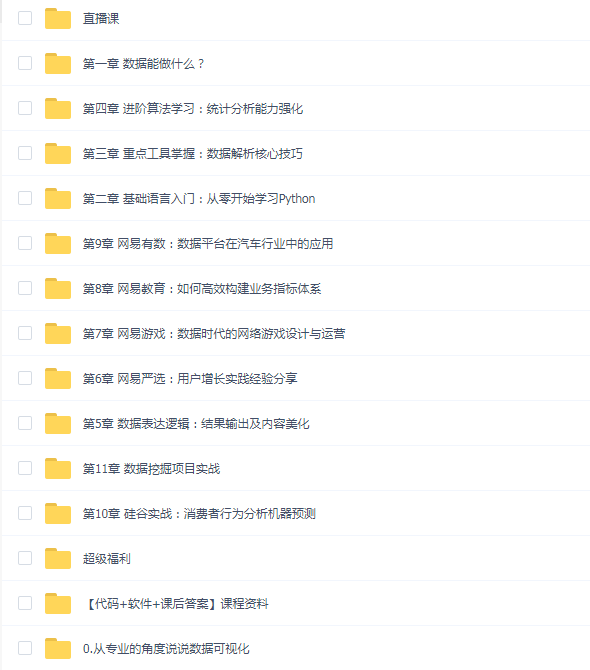
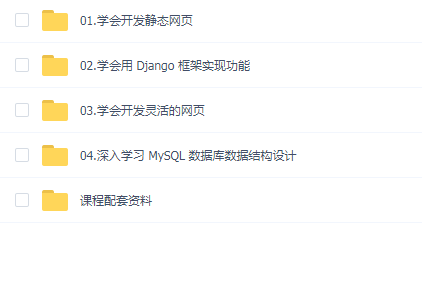
课程目录:
第一章节:Python网络爬虫之基础
1.课程介绍
2.Python初识
3.Python语法基础
4.Python控制流与小实例实战
5.Python函数详解
6.Python模块实战
7.Python文件操作实战
8.Python异常处理实战
9.Python面向对象编程实战
第二章节:Python网络爬虫之工作原理
1.网络爬虫初识:Excel表格自动合并作业讲解
2.网络爬虫初识:网络爬虫概述
3.网络爬虫工作原理详解
第三章节:Python网络爬虫之正则表达式
1.正则表达式实战:什么是正则表达式
2.正则表达式实战:原子
3.正则表达式实战:元字符
4.正则表达式实战:模式修正符
5.正则表达式实战:贪婪模式与懒惰模式
6.正则表达式实战:正则表达式函数
7.正则表达式实战:常见正则实例
8.简单爬虫的编写
9.作业讲解:出版社信息的爬取
第四章节:Python网络爬虫之浏览器伪装
1.Urllib基础
2.超时设置
3.自动模拟HTTP请求与百度信息自动搜索爬虫实战
4.自动模拟HTTP请求之自动POST实战
5.爬虫的异常处理实战
6.爬虫的浏览器伪装技术实战
7.Python新闻爬虫实战
8.作业讲解:博文信息的爬取
第五章节:Python网络爬虫之用户和IP代理池
1.糗事百科爬虫实战
2.用户代理池构建实战
3.IP代理池构建的两种方案实战
4.淘宝商品图片爬虫实战
5.作业讲解:同时使用用户代理池与IP代理池的方法
第六章节:Python网络爬虫之腾讯微信和视频实战
1.微信爬虫实战
2.抓包分析实战
3.腾讯视频评论爬虫思路介绍
4.腾讯视频评论爬虫实战-续
第七章节:Python网络爬虫之Scrapy框架
1.认识Scrapy框架
2.Scrapy框架安装难点解决技巧
3.Scrapy常见指令实战
4.Scrapy实现当当网商品爬虫实战
5.Scrapy模拟登录实战
6.Scrapy新闻爬虫项目实战(上)
7.Scrapy新闻爬虫项目实战(下)
8.Scrapy豆瓣网登陆爬虫与验证码自动识别项目实战1
9.Scrapy豆瓣网登陆爬虫与验证码自动识别项目实战2
10.如何在Urllib中使用XPath表达式
第八章节:Python网络爬虫之Scrapy与Urllib的整合
1.Scrapy与Urllib的整合使用1(以京东图书商品爬虫为例)
2.Scrapy与Urllib的整合使用2(以京东图书商品爬虫为例)
3.Scrapy与Urllib的整合使用3(以京东图书商品爬虫为例)
4.Scrapy与Urllib的整合使用4(以京东图书商品爬虫为例)
5.淘宝商品大型爬虫项目与自动写入数据库实战
第九章节:Python网络爬虫之扩展学习
1.补充内容:BeautifulSoup基础实战
2.补充内容:PhantomJS基础实战
3.补充:腾讯动漫爬虫项目实战1(JS动态触发+id随机生成反爬破解实战)
4.补充:腾讯动漫爬虫项目实战2(JS动态触发+id随机生成反爬破解实战)
第十章节:Python网络爬虫之分布式爬虫
1.分布式爬虫实现原理
2.分布式爬虫之Docker基础
3.分布式爬虫之Redis基础
4.分布式爬虫构建实战